



From Scientific Machines to Strategic Infrastructure
High Performance Computing (HPC) have undergone a fundamental transformation. Once associated primarily with academic supercomputers and niche scientific research, HPC systems are now core digital —powering artificial intelligence, industrial simulation, climate modelling, advanced manufacturing, and national technology strategies.
In 2026, High Performance Computers will no longer be defined solely by peak FLOPS. Instead, they are judged by time-to-solution, sustained performance, energy efficiency, scalability, and their ability to support mixed workloads across AI, simulation, and data analytics. As a result, decisions around HPC architecture, location, power, and delivery have become strategic infrastructure choices with long-term economic and operational consequences.
This article explores what High Performance Computing look like today, why it matters more than ever, how modern HPC systems are designed, and what organisations must consider when planning and delivering HPC infrastructure in a rapidly evolving landscape.
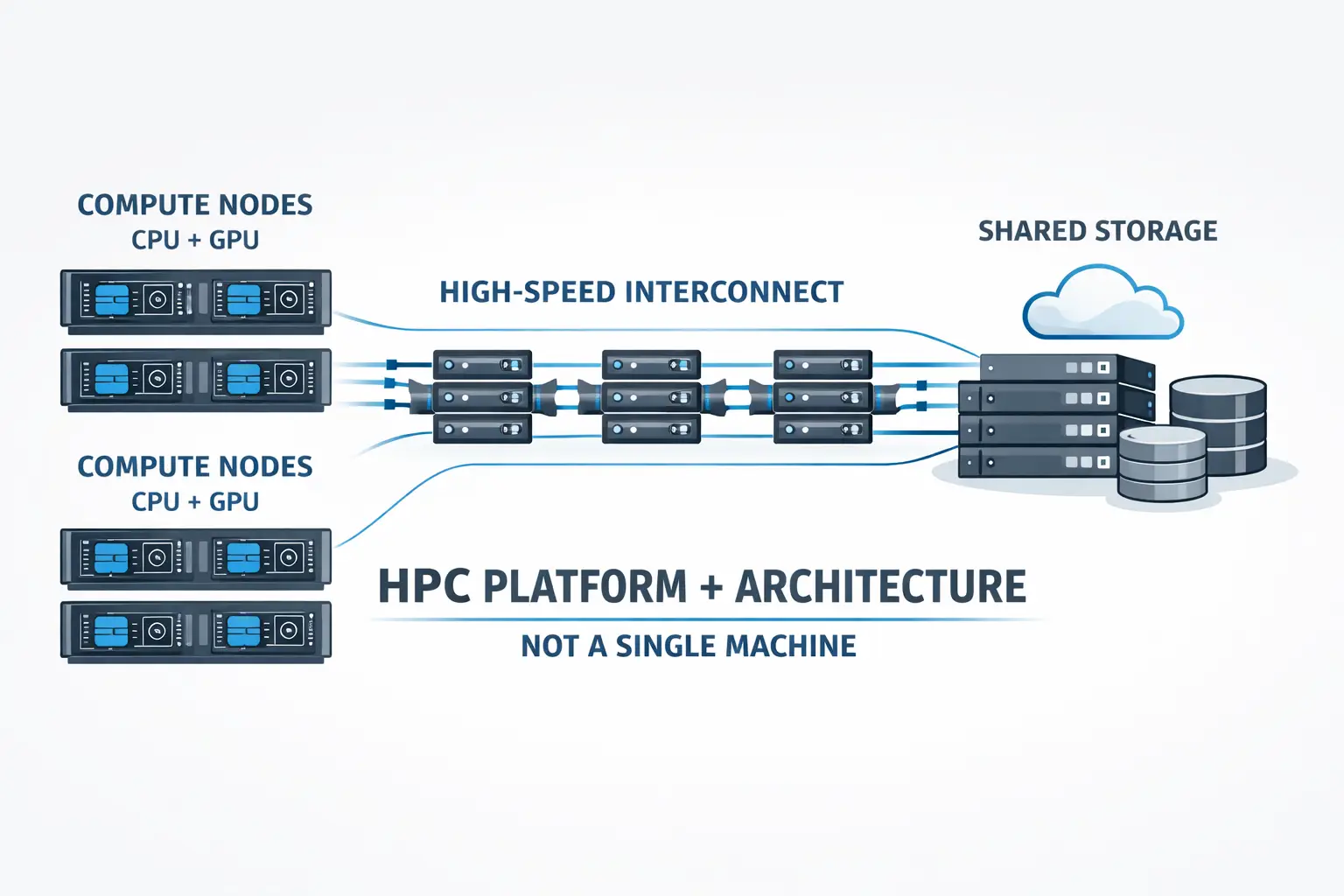
What Are High Performance Computers Today?
At its core, a High Performance Computer is a system designed to solve computational problems that are impractical or impossible for conventional IT infrastructure. Traditionally, this meant tightly coupled clusters running highly parallel scientific codes.
Today, that definition has expanded significantly.
Modern High Performance Computers are:
- Cluster-based platforms, not monolithic machines
- Built around CPU and accelerator combinations (GPUs, APUs, and specialised accelerators)
- Designed to run heterogeneous workloads, including:
- Large-scale simulations
- AI training and inference
- Digital twins
- Advanced analytics
Rather than serving a single class of users, HPC platforms increasingly support shared, multi-tenant environments spanning research, industry, startups, and public-sector use cases. This evolution has blurred historical boundaries between HPC, AI infrastructure, and advanced data center design—without eliminating their distinct requirements.
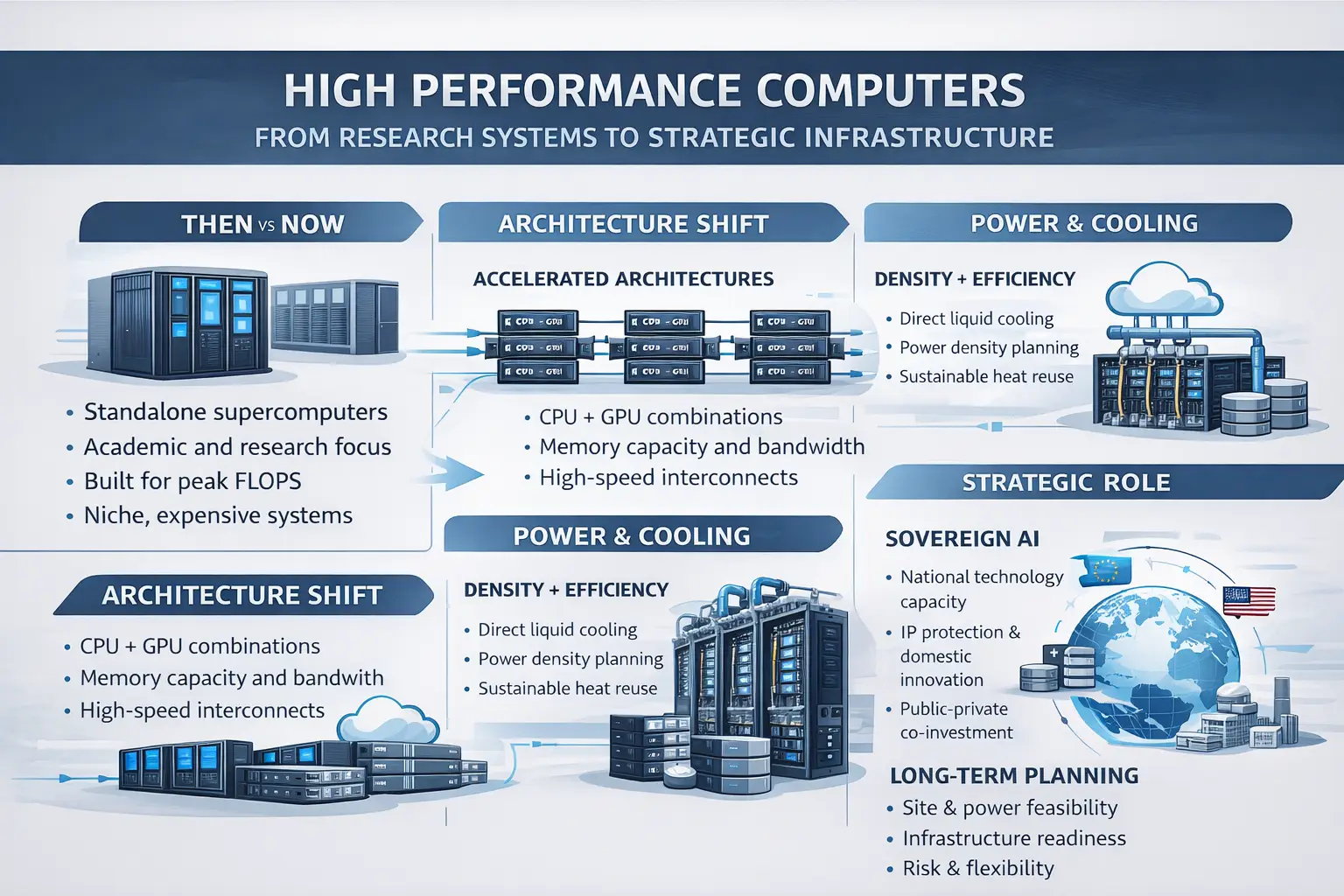
Why High Performance Computing Matters More Than Ever
Several converging forces have pushed HPC into the strategic spotlight:
AI-for-Science and Industrial AI
HPC systems are now central to:
- Training large AI models
- Running AI-enhanced simulations
- Combining physics-based models with machine learning
This convergence has dramatically increased demand for accelerated computing and high-bandwidth memory.
Energy, Climate, and Sustainability
High-resolution climate modelling, grid simulation, hydrogen research, and materials science depend on HPC-scale computation. These workloads are continuous, data-intensive, and increasingly mission-critical.
National and Regional Technology Strategies
Governments now view High Performance Computers as:
- Enablers of digital sovereignty
- Foundations for domestic AI capability
- Long-term strategic assets rather than research luxuries
As a result, HPC investment decisions are increasingly tied to policy, resilience, and industrial competitiveness, not just technical performance.
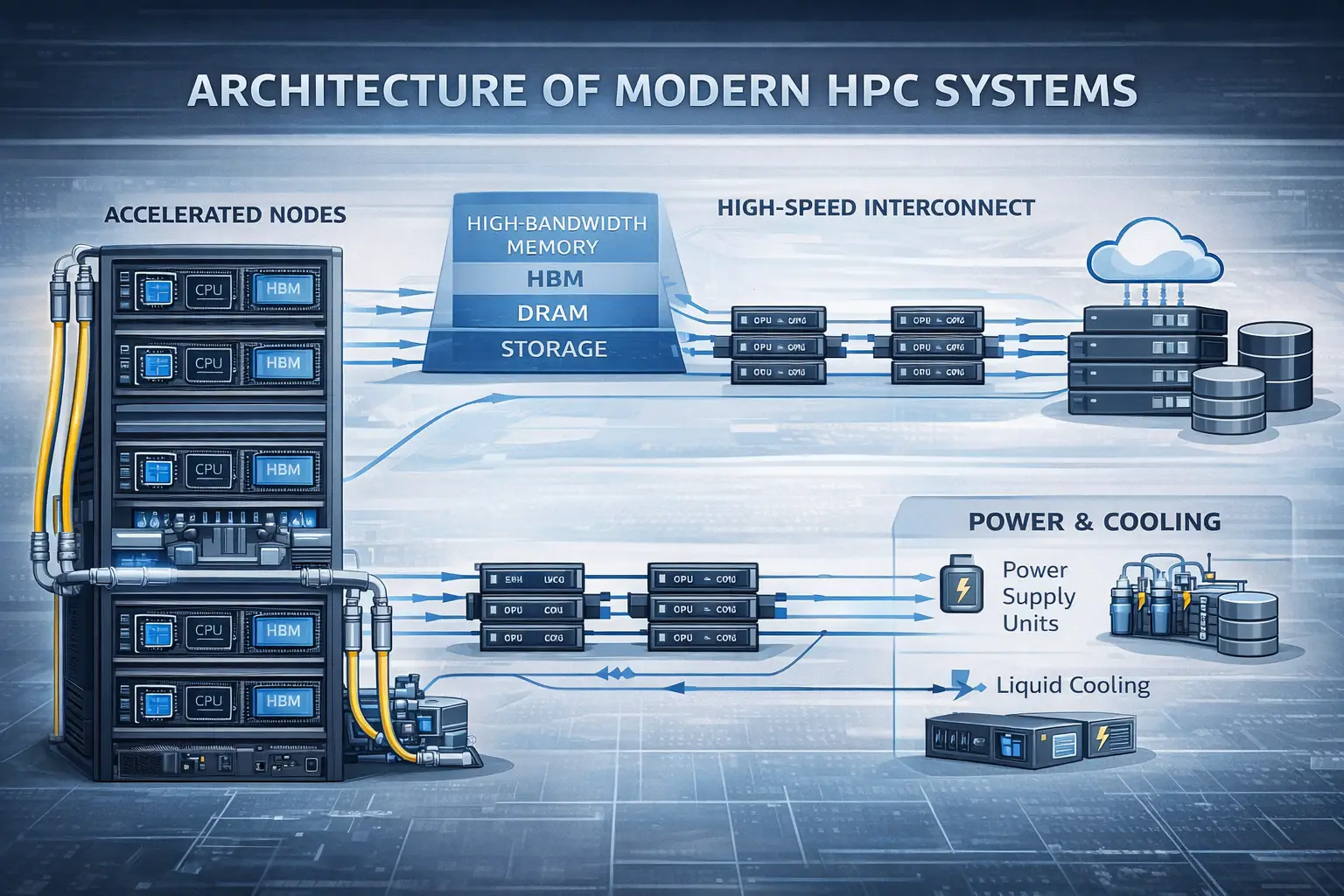
The Architecture of Modern High Performance Computing
Accelerated Compute as the Baseline
Modern HPC systems are designed around accelerators. GPUs and accelerator-rich nodes deliver orders-of-magnitude improvements in performance-per-watt for AI and simulation workloads, making them essential rather than optional.
Memory Is the Real Bottleneck
For many HPC applications, performance is constrained less by compute and more by:
- Memory capacity
- Memory bandwidth
- Data movement between nodes
High-bandwidth memory (HBM) and memory-aware software design now play a critical role in overall system effectiveness.
Power and Cooling as First-Order Constraints
High Performance Computers operate at extreme power densities. Liquid cooling, advanced power distribution, and heat management are now standard design considerations, tightly coupled to site selection and long-term operating cost.
The Fabric Is Part of the Computer
At scale, interconnect performance directly determines application efficiency. Low latency, high bandwidth, and congestion control are fundamental design parameters, not secondary considerations.

High Performance Computers and AI Data Centers: Related but Not Identical
While High Performance Computers and AI data centers increasingly share technologies—accelerators, high-speed networks, dense power delivery—their design drivers and operational models differ.
High Performance Computers are typically optimised for:
- Tightly coupled parallel workloads
- Predictable performance at scale
- Scientific and engineering accuracy
AI data centers often prioritise:
- Elastic scaling
- Inference throughput
- Commercial AI service delivery
Understanding where these models align—and where they diverge—is critical. A detailed comparison is explored in our dedicated article: HPC vs AI Data Centers
High Performance Computing as Strategic Infrastructure
One of the most significant shifts in recent years is the repositioning of HPC as long-term national and industrial infrastructure.
High Performance Computing is now:
- Anchor for regional innovation ecosystems
- Platform for public-private collaboration
- Trusted environment for sensitive data and intellectual property
This shift places new emphasis on:
- Governance models
- Access frameworks
- Long-term sustainability and expansion planning
HPC systems are no longer built for single projects—they are designed to serve evolving workloads over a decade or more.

Planning and Delivering High Performance Computer Infrastructure
While processor roadmaps and benchmarks attract attention, many HPC programmes succeed or fail based on non-compute decisions made early.
Critical planning considerations include:
- Site readiness: power availability, grid resilience, and physical constraints
- Scalability: phased growth without architectural dead ends
- Network integration: campus, metro, and wide-area connectivity
- Operational cost: energy consumption under sustained load
- Delivery governance: managing risk across complex, multi-year programmes
As HPC platforms become more complex and capital-intensive, independent feasibility studies, technical due diligence, and infrastructure planning play a decisive role in long-term success.

What’s Next for High Performance Computing (2026–2030)
Looking ahead, several trends will shape the next generation of HPC:
- A shift from peak performance metrics to throughput-per-watt and time-to-solution
- Larger, more tightly integrated accelerator domains
- Greater focus on memory scalability and data locality
- HPC platforms designed explicitly for mixed AI and simulation workflows
- Sustainability becoming a non-negotiable design constraint
Rather than chasing ever-higher theoretical performance, the future of High Performance Computing lies in efficient, usable, and resilient infrastructure.
Conclusion: High Performance Computing for Long-Term Decisions
High Performance Computing is no longer a deployment of specialist machines hidden in research labs. It is a strategic infrastructure platform that underpins AI, industrial innovation, and national capability.
As the role of HPC continues to expand, early-stage decisions—around architecture, location, power, scalability, and delivery—will determine not only technical performance, but economic viability and strategic value over time.
Plan Your High Performance Computer Infrastructure with Confidence
From feasibility and site readiness to delivery governance and long-term scalability, Azura Consultancy helps you de-risk HPC programmes and turn strategic computing ambitions into resilient, future-proof infrastructure.
How Azura Consultancy Supports High Performance Computer Programmes
As High Performance Computers evolve into long-term strategic infrastructure, the most critical risks rarely sit inside the compute hardware itself. They sit upstream—in strategy, feasibility, site readiness, power availability, network integration, and delivery governance.
Azura Consultancy supports organisations at this decisive front end, helping clients translate HPC ambitions into robust, buildable, and future-proof infrastructure programmes. Our work spans early-stage feasibility studies, site and power assessments, architecture-agnostic advisory, and technical due diligence—ensuring that HPC investments are aligned with operational realities, regulatory constraints, and long-term growth objectives from day one.
Crucially, Azura operates independently of OEMs and vendors. This allows us to focus on what is right for the programme, not what fits a particular product roadmap. We help public and private sector clients de-risk complex HPC initiatives by addressing scalability, energy efficiency, cooling strategies, network architecture, and delivery models before capital is committed.
As HPC platforms become foundational to AI, industrial innovation, and national capability, Azura provides the strategic, technical, and delivery-focused guidance required to turn high-performance computing from a technical ambition into resilient, sustainable infrastructure that performs over decades—not just at commissioning.






